

Recently got some great news from CoRL 2021, the conference on robot learning. Four papers of mine were accepted, covering different parts of the robotics problem. My hope is that these move us closer to understanding how we can build mobile manipulators that will be able to perform long horizon tasks alongside people, perhaps in their homes.
Specifically the papers are:
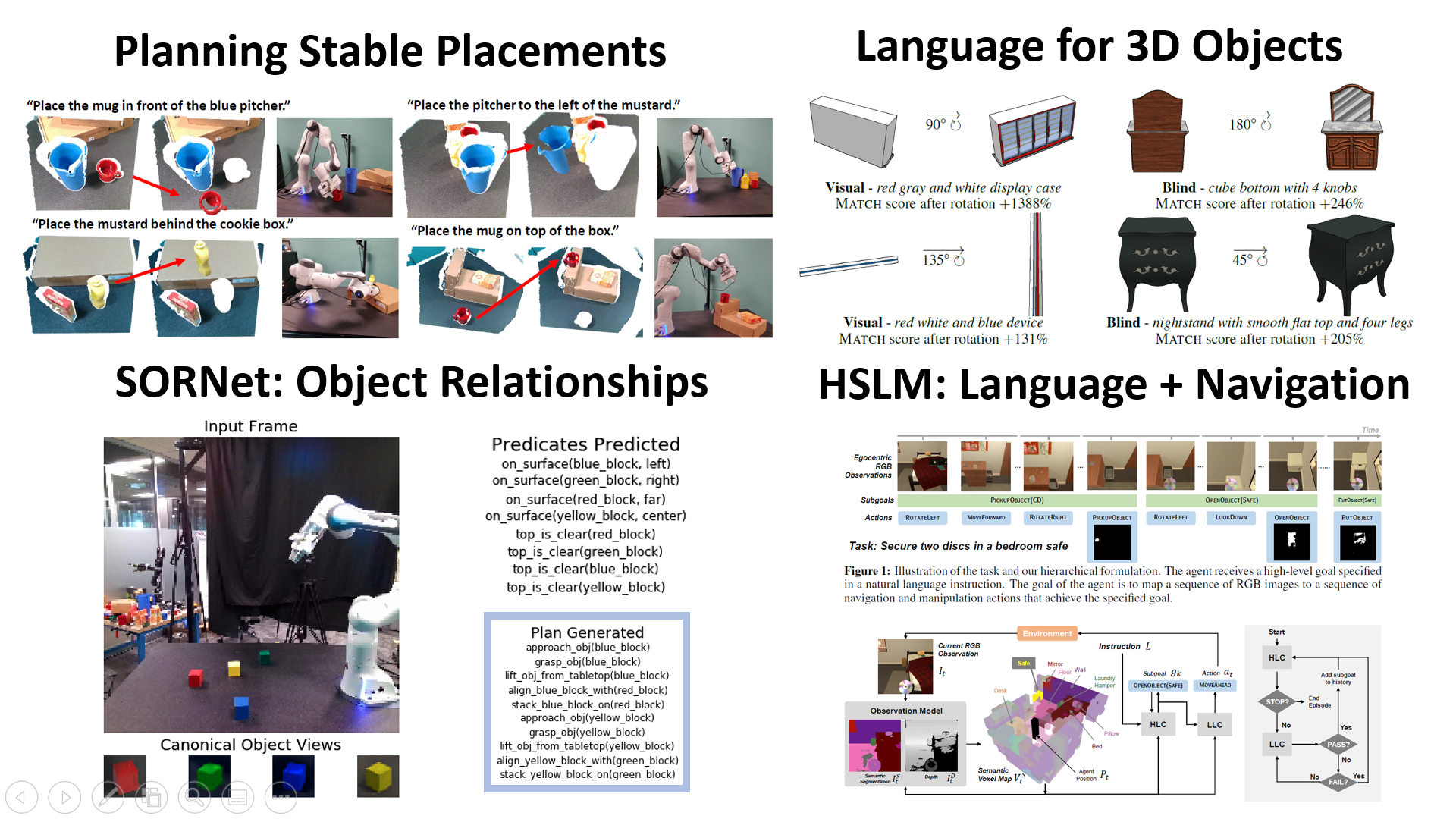
- SORNet: Spatial Object-Centric Representations for Sequential Manipulation - selected for oral presentation
- Predicting Stable Configurations for Semantic Placement of Novel Objects
- Language Grounding with 3D Objects
- A Persistent Spatial Semantic Representation for High-level Natural Language Instruction Execution - HLSM, winner of EVAL @ ECCV 2021 competition
SORNet
Authors: Wentao Yuan, Chris Paxton, Karthik Desingh, Dieter Fox
Sequential manipulation tasks require a robot to perceive the state of an environment and plan a sequence of actions leading to a desired goal state, where the ability to reason about spatial relationships among object entities from raw sensor inputs is crucial. Prior works relying on explicit state estimation or end-to-end learning struggle with novel objects. In this work, we propose SORNet (Spatial Object-Centric Representation Network), which extracts object-centric representations from RGB images conditioned on canonical views of the objects of interest. We show that the object embeddings learned by SORNet generalize zero-shot to unseen object entities on three spatial reasoning tasks: spatial relationship classification, skill precondition classification and relative direction regression, significantly outperforming baselines. Further, we present real-world robotic experiments demonstrating the usage of the learned object embeddings in task planning for sequential manipulation.

Key results: novel transformer architectures can capture very subtle relationships between objects from pixels alone and these representations transfer from simulation to the real world.
Link: SORNet: Spatial Object-Centric Representations for Sequential Manipulation
Stable, Semantic Placement
Authors: Chris Paxton, Chris Xie, Tucker Hermans, Dieter Fox
Human environments contain numerous objects configured in a variety of arrangements. Our goal is to enable robots to repose previously unseen objects according to learned semantic relationships in novel environments. We break this problem down into two parts: (1) finding physically valid locations for the objects and (2) determining if those poses satisfy learned, high-level semantic relationships. We build our models and training from the ground up to be tightly integrated with our proposed planning algorithm for semantic placement of unknown objects. We train our models purely in simulation, with no fine-tuning needed for use in the real world. Our approach enables motion planning for semantic rearrangement of unknown objects in scenes with varying geometry from only RGB-D sensing. Our experiments through a set of simulated ablations demonstrate that using a relational classifier alone is not sufficient for reliable planning. We further demonstrate the ability of our planner to generate and execute diverse manipulation plans through a set of real-world experiments with a variety of objects.

Key results: training a discriminator model for stability lets us do semantic rearrangement in unknown scenes with clutter and challenging geometry.
Link: Predicting Stable Configurations for Semantic Placement of Novel Objects
Language Grounding with 3D Objects
Authors: Jesse Thomason, Mohit Shridhar, Yonatan Bisk, Chris Paxton, Luke Zottlemayer
Seemingly simple natural language requests to a robot are generally underspecified, for example “Can you bring me the wireless mouse?” When viewing mice on the shelf, the number of buttons or presence of a wire may not be visible from certain angles or positions. Flat images of candidate mice may not provide the discriminative information needed for “wireless”. The world, and objects in it, are not flat images but complex 3D shapes. If a human requests an object based on any of its basic properties, such as color, shape, or texture, robots should perform the necessary exploration to accomplish the task. In particular, while substantial effort and progress has been made on understanding explicitly visual attributes like color and category, comparatively little progress has been made on understanding language about shapes and contours. In this work, we introduce a novel reasoning task that targets both visual and non-visual language about 3D objects. Our new benchmark, ShapeNet Annotated with Referring Expressions (SNARE), requires a model to choose which of two objects is being referenced by a natural language description. We introduce several CLIP-based models for distinguishing objects and demonstrate that while recent advances in jointly modeling vision and language are useful for robotic language understanding, it is still the case that these models are weaker at understanding the 3D nature of objects – properties which play a key role in manipulation.
Key results: CLIP is pretty good for object detection, especially with multiple views, even on very hard problems.
Link: Language Grounding with 3D Objects
Hierarchcial Language Spatial Model
Authors: Valts Blukis, Chris Paxton, Dieter Fox, Animesh Garg, Yoav Artzi
Natural language provides an accessible and expressive interface to specify long-term tasks for robotic agents. However, non-experts are likely to specify such tasks with high-level instructions, which abstract over specific robot actions through several layers of abstraction. We propose that key to bridging this gap between language and robot actions over long execution horizons are persistent representations. We propose a persistent spatial semantic representation method, and show how it enables building an agent that performs hierarchical reasoning to effectively execute long-term tasks. We evaluate our approach on the ALFRED benchmark and achieve state-of-the-art results, despite completely avoiding the commonly used step-by-step instructions.

Key results: spatial knowledge representations, hierarchical structure, and retrying different sub-problems lets you get state of the art performance on really challenging problems.
Link: A Persistent Spatial Semantic Representation for High-level Natural Language Instruction Execution